


RDEL #91: What makes production incidents in GenAI services different from traditional cloud incidents?
GenAI incidents are detected later, mitigated more slowly, and rooted in deep infrastructure complexity.

Welcome back to Research-Driven Engineering Leadership. Each week, we pose an interesting topic in engineering leadership, and apply the latest research in the field to drive to an answer.
As generative AI services like Azure OpenAI and Amazon Bedrock become core infrastructure, a pressing reliability challenge has emerged: production incidents in GenAI cloud services are uniquely hard to detect, triage, and resolve. Engineering teams now face a new class of incidents — driven by complex infrastructure, unpredictable model behavior, and immature monitoring. This week we ask: What makes production incidents in GenAI cloud services different from traditional cloud incidents — and how should engineering leaders adapt?
The context
Cloud reliability has long been a critical discipline for engineering teams, with decades of best practices built around detecting and resolving system failures, performance degradations, and deployment issues. However, generative AI introduces new complexity. Unlike traditional services, GenAI cloud systems combine massive model deployments, dynamic user-generated prompts, fine-tuning APIs, and multi-layered infrastructure dependencies.

This evolution means that failure modes aren’t just infrastructure-related — they include subtle problems like degraded model output quality (“hallucinations”), misbehavior triggered by user inputs, and unexpected interactions across layers of services. Additionally, because GenAI systems are newer and growing rapidly, their monitoring and incident response ecosystems are less mature, creating significant gaps in reliability operations.
The research
Researchers analyzed four years of production incidents from a major GenAI cloud provider (Microsoft), covering hundreds of thousands of incidents across services like Azure OpenAI. The study used Microsoft’s internal incident management database to categorize incidents by symptoms, root causes, and mitigation strategies, and compared GenAI incidents to traditional cloud service incidents.
Key findings:
GenAI incident have significantly higher reporting rates by humans and higher false alarm rates.
38.3% of GenAI incidents were reported by humans, vs. only 13.7% for traditional incidents. This is likely due to both (a) early releases of GenAI cloud services having low stability and (b) underdeveloped automated reporting tools.
Monitored GenAI incidents had an 11.0% false alarm rate, compared to 3.8% for traditional services.
Common symptoms impact both site reliability and user experience.
49.8% involved degraded service performance.
35.7% involved deployment failures (models or infrastructure).
14.5% involved invalid or low-quality inference outputs .
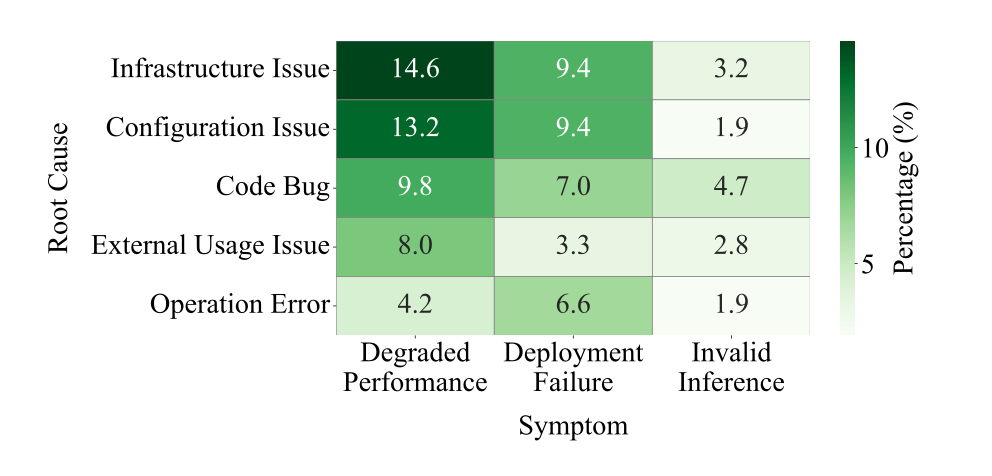
Root causes vary.
The most common causes were infrastructure issues (27.2%), configuration errors (24.5%), and code bugs (21.5%).
Many symptoms could arise from multiple root causes, complicating diagnosis.

The relationship between symptom and root cause Mitigation takes significantly longer, leading to longer customer impact.
GenAI incidents took on average 1.12x longer to resolve than traditional cloud incidents.
The presence of troubleshooting guides significantly improved incident management times. Similarly, incidents detected through monitors were significantly faster to manage because they often included troubleshooting guides alongside the finding.

TTM distribution across different factors: Y-axis is the normalized TTM of all incidents across (a) Different severity levels, (b) The presence of a TSG, and (c) Detection types. Resolutions by category included:
Ad-hoc fix (ie short term “patches” to fix behavior) (22.4%)
Self recover (19.7%)
Rollbacks (15%)
Configurations changes (13%)
Infrastructure fix (12.1%)
External fix (10%)
Code fix (7.6%)


The application
This research highlights an urgent reality: GenAI cloud services demand a new approach to reliability engineering. Traditional monitoring, triage, and mitigation processes aren’t enough.
To apply these findings, engineering leaders should:
Invest early in GenAI-specific observability:
Improve automated detection of quality degradation, invalid inference, and model behavior changes — not just system performance metrics.
Prioritize fast rollback and flexible mitigation playbooks:
Since diagnosing GenAI incidents can be slower, focus on restoring service quickly via rollbacks, feature toggles, or dynamic throttling, then investigate root causes after stabilization.
Strengthen infrastructure resilience and resource scaling:
Infrastructure issues (e.g., GPU failures, network bottlenecks) are a leading cause of GenAI incidents. Leaders should proactively scale, monitor, and maintain GPU-heavy infrastructure with specialized reliability engineering efforts.
Continuously measure and prioritize friction points before they escalate:
GenAI incidents often stem from subtle infrastructure bottlenecks, configuration drift, or unobserved usage patterns. Regularly identifying emerging areas of friction — and prioritizing fixes before they trigger incidents — can dramatically reduce mean time to detection and mitigation.
As GenAI services reshape the cloud landscape, engineering leaders who proactively invest in better observability, faster mitigation strategies, and continuous friction reduction will be the ones who build the most resilient and reliable systems.
—
Happy Research Tuesday!
Lizzie
Good read, thanks for sharing this! Kind of wild to accept ‘hallucinations’ as just another failure. Imagine explaining that in a postmortem 10 years ago. 😄
Thanks a lot for sharing - not only insightful for genAI incidents, but also good questions to ask for better analysis of regular incidents.