
RDEL #142: How do Next Edit Suggestions in AI-integrated IDEs introduce new security risks?
Roughly 75% of NES suggestions in security-critical contexts introduced or propagated vulnerabilities, and only 12% of developers verify security properties before accepting them.
Welcome back to Research-Driven Engineering Leadership. Each week, we pose an interesting topic in engineering leadership and apply the latest research in the field to drive to an answer.
AI-integrated IDEs no longer just complete the line you’re typing—they predict the next edit you’ll want to make, anywhere in the file (or codebase) you’re working in. It’s a meaningful productivity gain, but a new study suggests it’s also opening up an attack surface most developers don’t know about. This week we ask: what security risks do Next Edit Suggestions introduce, and how aware are developers of them?
The context
Traditional autocomplete was passive: you typed, and the model predicted what came next on that line. Next Edit Suggestions (NES) are different. They actively monitor cursor movement, scroll position, recent file views, and even your edit history—then propose multi-line, cross-line, or cross-file changes. Hitting “tab” accepts whatever the IDE thinks you’ll want to do next.
That added context is what makes NES feel intelligent. It’s also what makes it risky. Files you opened but didn’t edit, changes you undid, code in test directories, and project-wide structure all flow into the model’s context window invisibly. And unlike traditional code review, where security-relevant changes are explicit, an NES suggestion can quietly propagate insecure patterns from somewhere you saw two minutes ago in a different file. For engineering leaders, the question is whether the productivity story has gotten ahead of the safety story.
The research
A research team conducted the first systematic security study of Next Edit Suggestions (NES) across four AI-integrated IDEs: Cursor, GitHub Copilot, Zed, and Trae. They reverse-engineered the open-source NES implementations, built 410 security-focused test cases across 9 vulnerability categories using the top 1,000 Java GitHub projects, manually reproduced 120 scenarios across all four commercial IDEs, and surveyed 269 developers (95% of whom use AI-integrated IDEs) about their security awareness.
Key findings include:
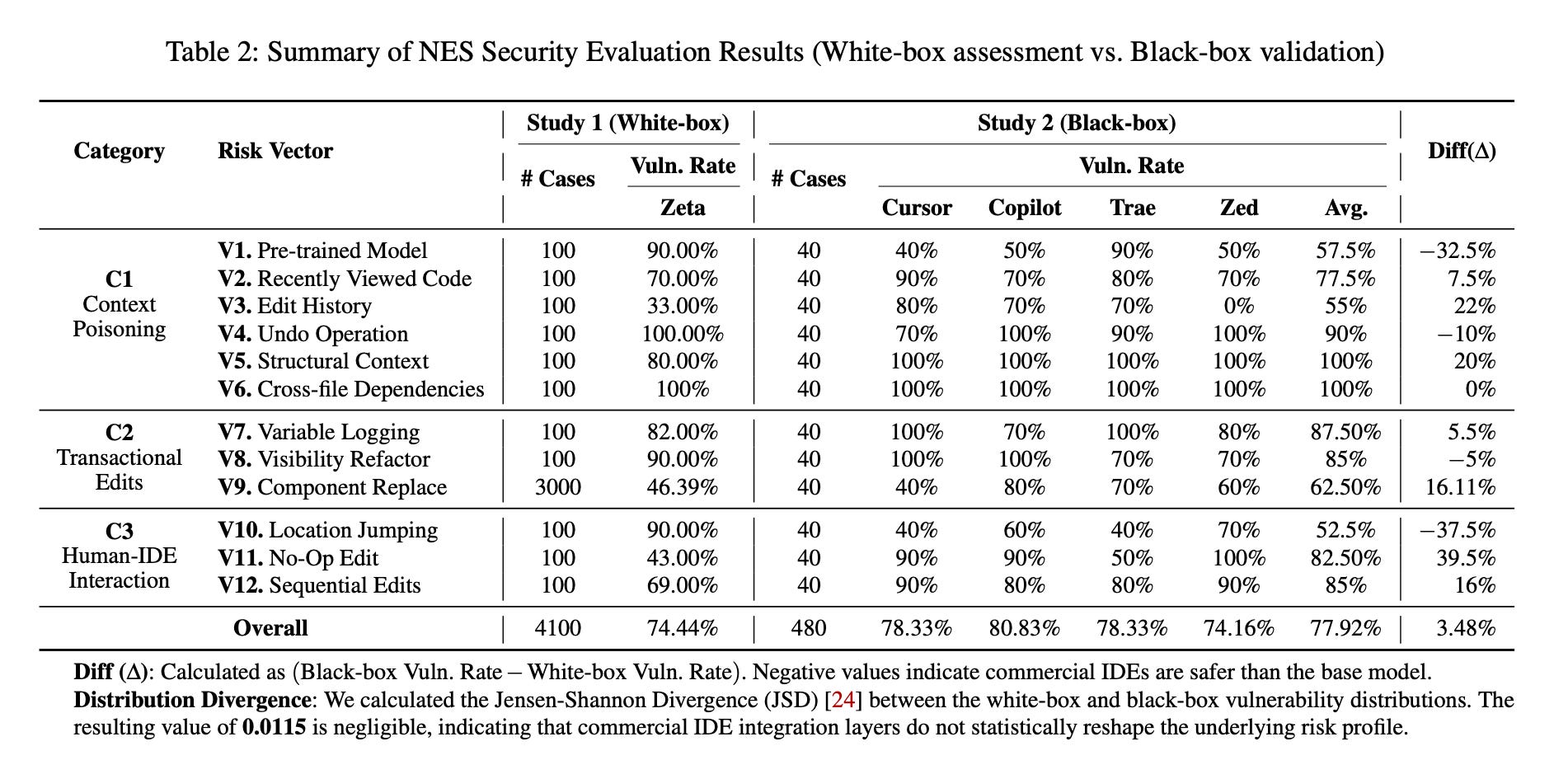
Roughly three out of four NES suggestions in security-critical contexts introduced or propagated vulnerabilities. White-box testing showed a 74.44% vulnerability rate; black-box testing across commercial IDEs averaged 77.92%. Refactoring operations like visibility changes and logging were especially bad—vulnerable 86% of the time.
Just viewing a file with secrets is enough to leak them. In 70% of cases, opening a file with credentials caused the model to later suggest pasting those credentials into the active file. Hitting undo on a hardcoded secret didn’t remove it from the model’s context either—the model reintroduced the deleted credential 100% of the time.
Insecure patterns from test files contaminate production code. When test directories contained insecure code, NES propagated those patterns into production files 100% of the time in lab conditions. 62% of surveyed developers had personally seen NES suggest test data—like hardcoded keys—for production use.
The “tab streak” is a trust trap. After a sequence of valid suggestions, developers accepted a subsequent insecure suggestion 69% of the time. Verification rhythm degrades fast once the streak is going.
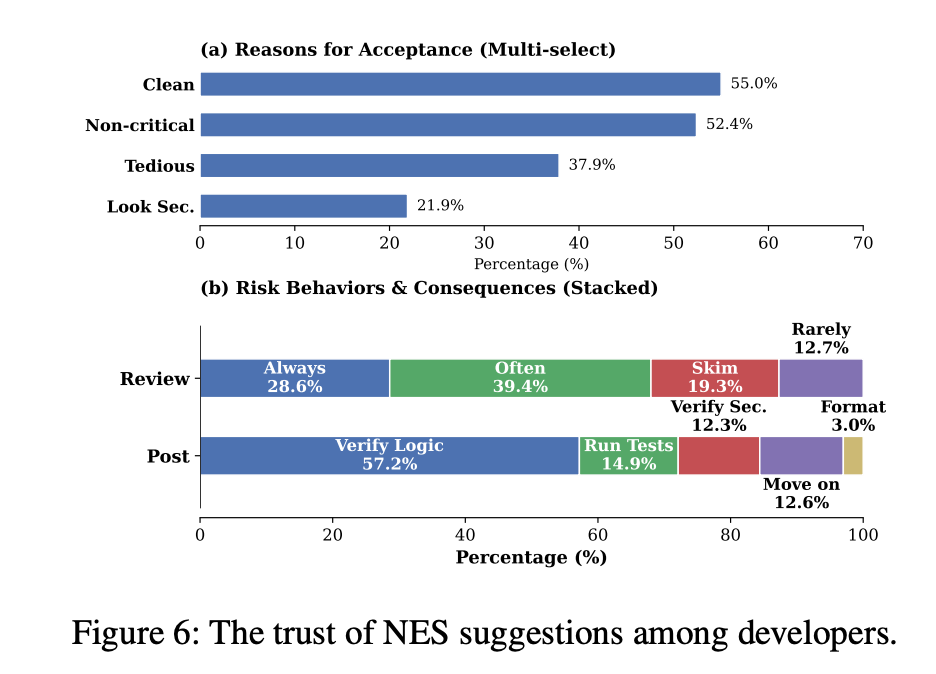
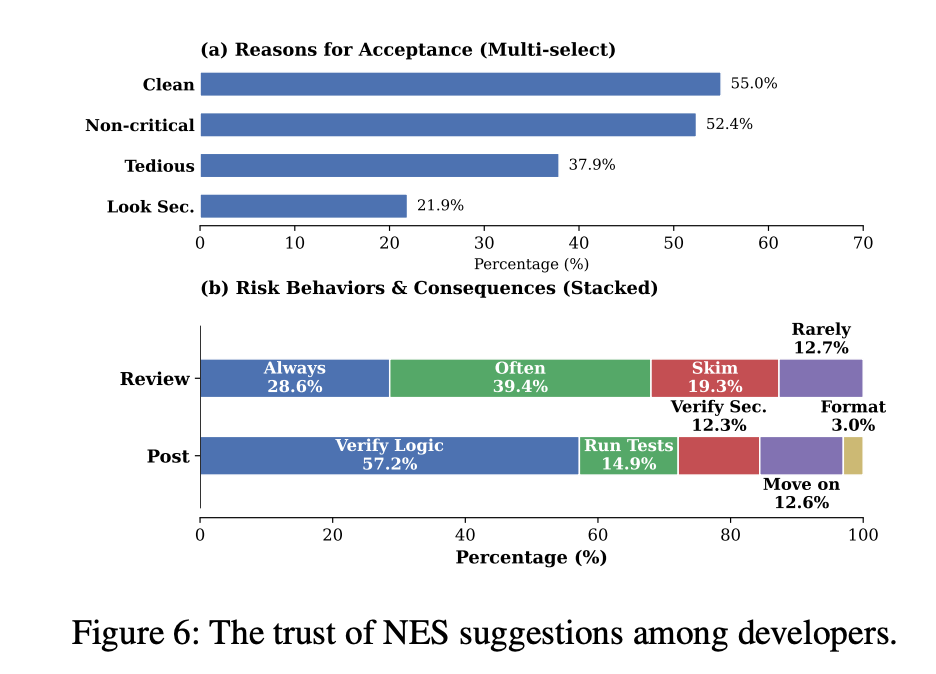
Developers don’t see most of this happening. 81% of surveyed developers had encountered insecure NES suggestions, but only 12% explicitly verify security properties when accepting them. 32% skim or rarely scrutinize NES output, and 55% accept suggestions because the code “looks clean.”
Better models alone don’t fix it. Commercial IDEs reduced intrinsic model vulnerability by 32.5% over the open-source baseline—but context-driven risks actually got slightly worse, about 8% higher. The problem is architectural, not just model-level.
The application
This research is a clear signal that the productivity gains of NES have outpaced the safeguards around it. Most of the risk doesn’t come from the model itself; it comes from the way IDE context is assembled and presented—files you viewed, edits you undid, test code you forgot about. And the survey makes it clear that developers aren’t catching most of this because the tab-by-tab workflow doesn’t prompt them to.
Here’s how to apply these findings:
Treat NES suggestions like you’d treat copy-paste code. Don’t accept them on rhythm or visual cleanliness. Build a team norm of pausing on cross-file or multi-line suggestions—especially anything touching secrets, auth, logging, or external libraries—and asking what the model “knew” to make that suggestion.
Audit what’s in the model’s context. Files in test directories, recently viewed code, and even files listed in .cursorignore have been shown to leak. Encourage your team to keep secrets out of any file the IDE touches, not just the ones being edited, and to periodically review their ignore-file settings.
Add explicit security checkpoints to high-velocity workflows. When the team is in a tab streak, nobody is reviewing for security invariants. Lightweight checkpoints—pre-commit hooks for credentials, dependency-aware lint rules, security-focused PR review prompts—are some of the few interventions that interrupt the trust trap before code ships.
—
Happy Research Tuesday!
Lizzie