
RDEL #129: What keeps AI-generated pull requests from getting merged into production?
Security and testing gaps are the most likely reasons an AI-generated PR gets rejected — but docs and style issues are the ones teams actually fix.
Welcome back to Research-Driven Engineering Leadership. Each week, we pose an interesting topic in engineering leadership and apply the latest research in the field to drive to an answer.
AI coding agents are shipping pull requests at a pace that would be impossible for human developers alone — but that speed can pose challenges if reviewers can’t keep up, or if the code keeps getting rejected. Nearly 70% of agent-authored PRs face longer review times, go unreviewed entirely, or get rejected outright, making the review process one of the biggest bottlenecks in human-AI collaboration. This week we ask: What themes dominate code reviews of AI-authored pull requests, and how do they differ between accepted and rejected PRs?
The context
As agentic AI coding tools become a standard part of engineering workflows, the focus has largely been on what these tools can generate. But generation is only half the equation. Once an AI agent opens a pull request, a human reviewer still has to evaluate it, and that review process is where a lot of value (or friction) gets created.
AI agents don’t yet have a strong internal sense of what makes code reviewable. They can write functional code, but they may skip documentation, introduce unnecessary changes, or overlook security implications — the kinds of things that a human developer would often self-correct before submitting. Understanding exactly where these gaps are concentrated gives engineering leaders a much clearer signal on where to focus human oversight, and where AI agents need to improve before that oversight can be reduced.
The research
Researchers at UC Irvine conducted a large-scale empirical study analyzing 19,450 inline code review comments across 3,177 agent-authored pull requests drawn from real-world GitHub repositories and categorized reviews into 12 thematic categories. They then compared review patterns between PRs that were successfully merged and those that were rejected.
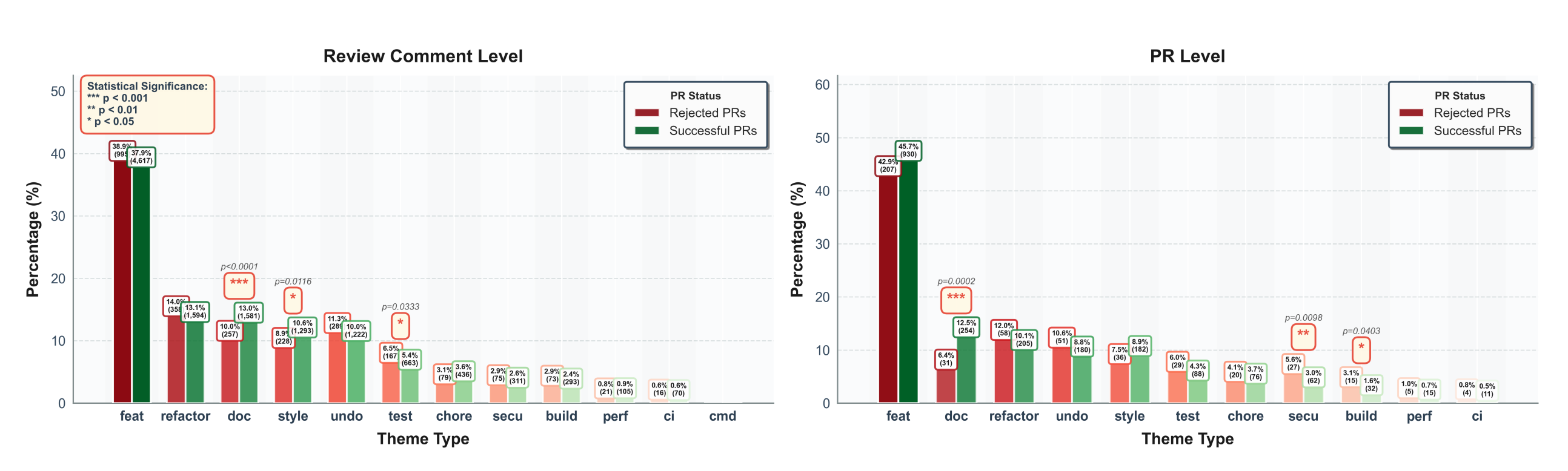
Key findings:
Feature development and functional correctness dominated reviews, but didn’t differentiate accepted from rejected PRs. Comments related to core implementation and logical changes accounted for 38.5% of all review comments and were the top theme in 46.5% of PRs — in both accepted and rejected cases. This suggests reviewers are spending significant time on substance regardless of outcome.
Documentation and styling issues were significantly more common in accepted PRs. Documentation gaps appeared in 12.97% of accepted PR comments vs. 10.05% in rejected ones (p < 0.001), and styling concerns showed a similar pattern (10.61% vs. 8.91%, p < 0.05).
The implication: reviewers are willing to work through these issues when the core logic is sound — they’re constructive friction, not dealbreakers.
Testing and security concerns were significantly more common in rejected PRs. Testing issues appeared in 6.53% of rejected PR comments vs. 5.44% in accepted ones (p < 0.05). At the PR level, security emerged as an even stronger rejection signal — appearing as a dominant theme in 5.59% of rejected PRs vs. just 3.05% of accepted ones (p < 0.01). These are the issues that stop a merge.
Build and configuration problems also trended toward rejection. Build-related themes appeared in 3.11% of rejected PRs vs. 1.57% of accepted ones (p < 0.05), pointing to environment and setup issues as another common blocker for AI-generated code.
“Undo” and revert comments were notably more prevalent in rejected PRs. While not statistically significant at the threshold used, the pattern was consistent: AI agents frequently make unnecessary changes that reviewers ultimately reject, adding noise to the review process and eroding trust.
The application
AI coding agents are advanced enough to get code written, but not yet refined enough to get it merged without meaningful human review. The good news is the reasons why are largely predictable and addressable. The gap isn’t in raw capability; it’s in the details that experienced engineers internalize but AI agents still miss.
Here’s how to act on this:
Prioritize human review on security, testing, and build configuration. These are the categories most likely to kill a PR. Rather than reviewing everything equally, engineering leaders should direct senior attention toward these areas first when reviewing agent-authored code. Treat them as the non-negotiables.
Build pre-merge checklists for AI-generated PRs that surface the known weak spots. Documentation, test coverage, and security checks should be explicit gates — not afterthoughts. If your team is adopting agentic tools, the workflow around them matters as much as the tools themselves.
Track “undo” and revert rates as a health metric for your AI tooling. Unnecessary changes are a signal that the agent isn’t scoping its work well. If reviewers are spending time reverting agent commits, that’s a signal to tighten the prompts or constraints you’re giving the tool — before it hits review.
—
Happy Research Tuesday!
Lizzie
Really insightful breakdown on where AI code review friction actually lives. The split between "rejection blockers" (security, testing) and "fixable issues" (docs, styling) is key for anyone managing AI-assisted dev teams. What stood out to me was the undo/revert pattern, that's a trust errosion metric most teams probably arent tracking yet. I've sen this firsthand where agents makea bunch of unnecessary refactors that add noise, reviewers start ignoring agent PRs entirely after that.