
RDEL #110: How often do LLMs warn developers about security vulnerabilities in their code?
Even the best-performing LLM only warns about security issues 40% of the time, creating false confidence in code safety.
Welcome back to Research-Driven Engineering Leadership. Each week, we pose an interesting topic in engineering leadership and apply the latest research in the field to drive to an answer.
LLMs like ChatGPT, Claude, and others have become integral tools for software development, with >92% of U.S.-based developers using generative models for daily tasks. While these AI assistants excel at generating code and answering programming questions, they may be creating a hidden security risk that engineering leaders need to understand. This week we ask: how often do LLMs warn developers about security vulnerabilities in their code?
The context
The rapid adoption of conversational AI in software development has fundamentally changed how developers solve problems and learn new techniques. Developers routinely share code snippets with LLMs when debugging, seeking optimization advice, or learning new frameworks. However, this interaction pattern creates a concerning scenario: what happens when the code being shared contains security vulnerabilities that the developer hasn't recognized?
Unlike traditional code review processes where security-conscious peers might spot issues, LLMs operate as black boxes with unclear security awareness capabilities. If a developer unknowingly shares vulnerable code—perhaps copied from Stack Overflow or written without security considerations—and the LLM simply addresses the functional question without highlighting security flaws, it could reinforce poor security practices. This creates a multiplier effect where insecure code patterns get validated and potentially propagated across development teams. The stakes are particularly high given that recent studies have found AI-assisted developers produce more vulnerable code while feeling more confident about its security.
The research
Researchers conducted a comprehensive evaluation of security awareness in three major LLMs: GPT-4, Claude 3, and Llama 3. They created a dataset of 300 Stack Overflow questions containing vulnerable code snippets, split into two groups: questions where security issues had been mentioned by the community, and questions where vulnerabilities went unnoticed. Each LLM was prompted with these questions to evaluate whether they would proactively warn about security issues.
The key findings reveal concerning gaps in LLM security awareness:
LLMs rarely warn about vulnerabilities without explicit prompting: The best performing model (GPT-4) only warned users about security issues in 40% of cases in the most favorable conditions, dropping to just 16.6% when code had been modified to reduce training data overlap.
Performance varies dramatically by vulnerability type: LLMs detected issues related to sensitive information exposure (like hardcoded credentials) 29.6% of the time, but struggled with vulnerabilities involving external control of file paths, detecting these only 11.1% of the time.
Training data exposure significantly impacts detection: All models performed substantially better on questions that likely appeared in their training data, with detection rates dropping by more than half on transformed code that hadn't been seen before.
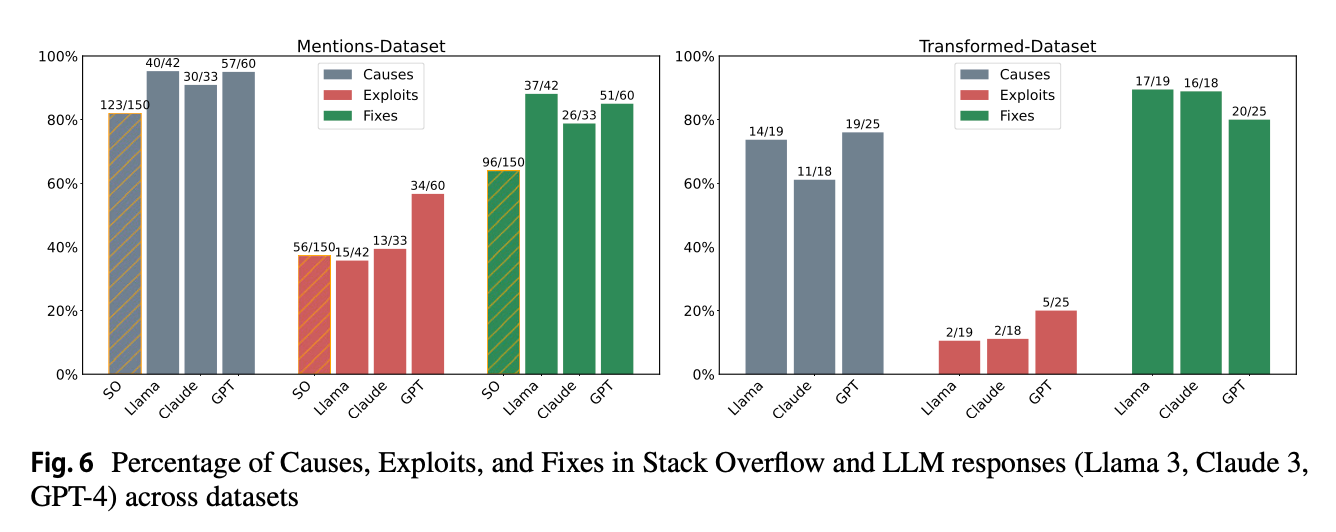
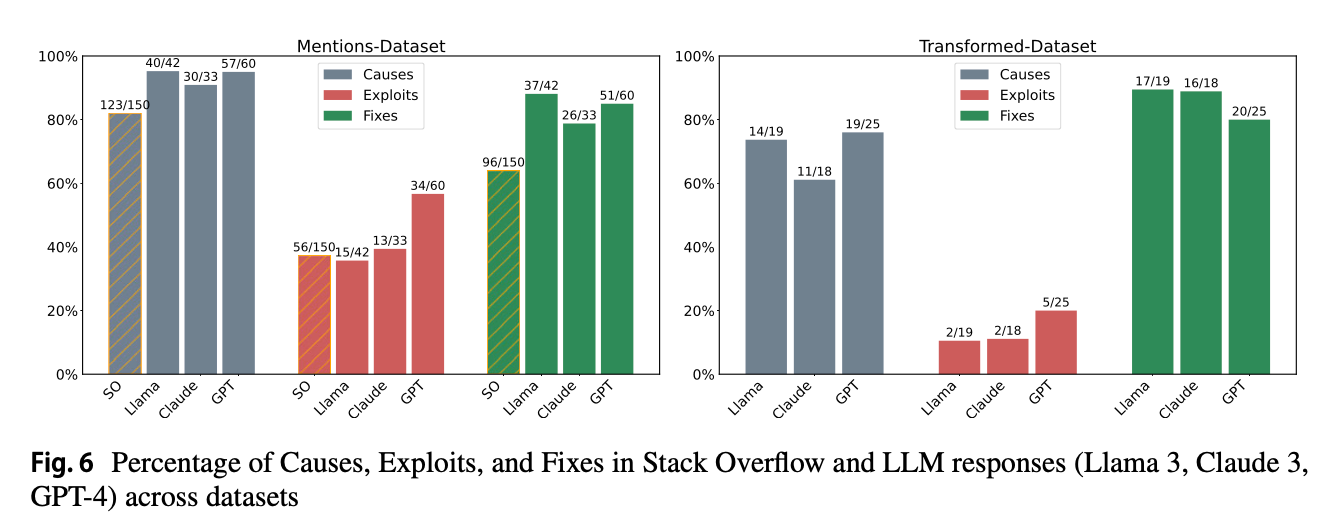
When LLMs do identify security issues, they provide comprehensive guidance: In cases where security warnings were issued, LLMs provided more detailed information about causes, exploits, and fixes compared to typical Stack Overflow responses, with GPT-4 particularly excelling at explaining potential exploits.
Simple prompt modifications can improve security awareness: Adding phrases like "Address security vulnerabilities" to prompts increased GPT-4's detection rate to 76% for familiar code, though improvements were limited for novel code patterns.
The application
This research exposes a significant security risk in LLM-assisted development: these tools consistently fail to identify vulnerabilities, with even the best model missing 60% of security issues. This creates a dangerous scenario where developers receive functional solutions while security flaws go unaddressed and potentially reinforced.
Engineering leaders should take several concrete actions to mitigate these risks:
Implement security-focused prompt engineering standards: Train developers to explicitly request security reviews in their LLM interactions by adding phrases like "Address security vulnerabilities" or "Check for security issues" to their queries, while recognizing this only provides partial protection.
Integrate static analysis tools into LLM workflows: Develop processes that automatically run code through security analysis tools like CodeQL before or alongside LLM consultations, as research shows this dramatically improves vulnerability detection rates to over 80%.
Establish LLM-aware code review processes: Modify existing code review practices to specifically account for LLM-generated or LLM-reviewed code, with reviewers trained to look for common vulnerability patterns that these models tend to miss, particularly around input validation and access controls.
While LLMs will likely improve over time, the reality is that they miss critical security issues more often than they catch them. By implementing the security-focused practices outlined above, engineering leaders can enable their teams to leverage AI coding assistance without compromising on the security discipline that modern software development demands.
—
Happy Research Tuesday,
Lizzie
Super interesting, thank you! There was also the research from the folks at Sonar, looking into quality and vulnerability metrics: https://arxiv.org/pdf/2508.14727#page15