
RDEL #102: How Does AI Disrupt Accountability in Code Reviews?
Researchers show that intrinsic drivers like pride and integrity shift in peer review—but disappear when feedback comes from an AI.

Welcome back to Research-Driven Engineering Leadership. Each week, we pose an interesting topic in engineering leadership, and apply the latest research in the field to drive to an answer.
Code review is one of the few rituals that shape both quality and culture in engineering teams. It’s not just a gate for correctness—it’s a moment where developers stake their professional reputation, express pride in their work, and respond to peer expectations. But as AI tools begin assisting or even replacing human reviewers, an important question remains: How does LLM-assisted code review affect software engineers’ accountability for code reviews?
The context
Code review isn’t just about catching bugs—it’s one of the few rituals in software development that blends technical scrutiny with social accountability. When engineers submit code for review, they’re not only seeking correctness—they’re signaling craftsmanship, upholding shared standards, and reinforcing team norms. Knowing a teammate will read your code creates a subtle but powerful form of pressure to do good work.
That pressure is often driven by intrinsic motivations—like pride, integrity, and professional reputation. Peer review activates those drivers because it’s fundamentally human: there’s feedback, judgment, reciprocity. But as teams adopt LLMs to assist with or even automate reviews, this social fabric starts to fray. AI tools might give accurate feedback, but can they replicate the accountability that comes from being seen by a peer? And if not, what do we lose when the reviewer is a machine?
The research
The researchers conducted a two-phase qualitative study to examine how accountability operates in code review, and how it changes when AI is introduced. In Phase I, they interviewed 16 software engineers to identify intrinsic motivators behind accountability for code quality. In Phase II, they ran four focus groups simulating both peer-led and LLM-assisted reviews to observe how these dynamics play out in practice.
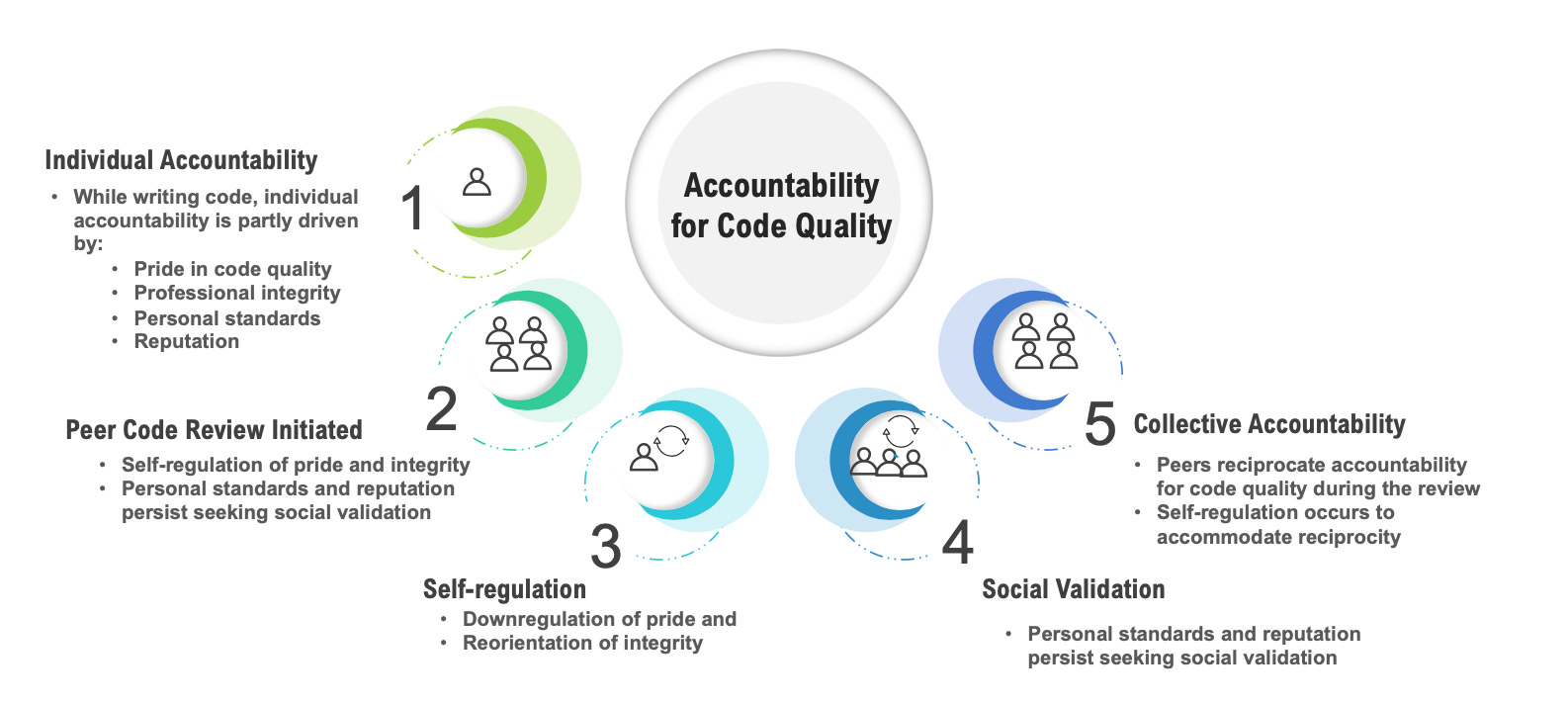
Key findings:
Four intrinsic drivers shape individual accountability: Developers reported that they feel responsible for code quality due to:
Personal standards: “I want to do it like the highest quality that whatever I can deliver” (P8)
Professional integrity: “My integrity matters, because I want my code to survive beyond my tenure” (P15)
Pride in code quality: “I feel proud and more happy more often” (P13)
Professional reputation: “If my code quality is good, my image as a developer is good” (P11)
Code review initiated a shift from individual to collective accountability. Developers described consciously adjusting their tone and openness to feedback as soon as a review began—modulating pride, reframing integrity, and aligning their personal standards with team norms. As one participant put it, “we need to hold each other accountable and ourselves accountable.”
LLM-assisted reviews disrupted this process. Developers did not experience the same shift toward collective ownership when receiving feedback from an AI. Without a human audience, there was no reciprocity—no social contract to uphold. As one engineer noted, “you cannot hold the model accountable.”
Participants saw AI as a useful assistant, not a partner. Many said they would use LLMs for a first pass—to catch low-level issues before requesting peer review—but would not rely on them to drive meaningful accountability or reinforce shared standards.
Engineers were often impressed with the comments but remained skeptical of the tool’s contextual understanding. Feedback was seen as useful, but not authoritative.
The application
This study highlights that code review is not just a technical checkpoint—it’s a human ritual that fosters accountability, learning, and team cohesion. Engineers feel responsible not only because of code quality standards, but because of how the team evaluates their works. When LLMs replace the process, intrinsic motivation and shared ownership often fade.
That doesn’t mean LLMs have no place in the code review process, and in fact, there are meaningful opportunities for LLMs to support the process to improve overall productivity—catching low-level issues, offering suggestions, or helping less experienced developers. But we must recognize that code review is also fundamentally a human experience, where trust is built and teams align on what “good” looks like.
In a time where maturity of LLMs in the code review process necessitates both humans and machines together, here’s how engineering leaders can apply the findings of this study:
Use LLMs as a support layer. Let AI handle rote issues or serve as a first-pass reviewer, while keeping peer review central for feedback, mentorship, and accountability.
Embed human checkpoints to preserve collective accountability. Ensure every review cycle still includes human input, especially on decisions that impact architecture, maintainability, or team standards. Reinforce that shared accountability comes from peer-to-peer interaction, not just tooling.
Reinforce intrinsic drivers through social norms, not process alone. LLMs won’t care about pride or professional reputation—but your team will. Recognize thoughtful reviews, model high standards, and create space for engineers to take ownership and feel seen, even in an AI-augmented workflow.
Done well, AI can elevate code quality—but it’s human interaction that holds teams together.
—
Happy Research Tuesday,
Lizzie